
Proactive Autoscaling for Edge Applications in Kubernetes
 Admin
Admin
Proactive Autoscaling for Edge Applications in Kubernetes
Kubernetes Horizontal Pod Autoscaler (HPA)’s delayed reactions might impact edge performance, while creating a custom autoscaler could achieve more stable scale-up and scale-down behavior based on domain-specific metrics and multiple signal evaluations.
Startup time of pods should be included in the autoscaling logic because reacting only when CPU spiking occurs delays the increase in scale and reduces performance.
Safe scale-down policies and a cooldown window are necessary to prevent replica oscillations, especially when high-frequency metric signals are being used.
Engineers should maintain CPU headroom when autoscaling edge workloads to absorb unpredictable bursts without latency impact.
Latency SLOs (p95 or p99) are powerful early indicators of overload and should be incorporated into autoscaling decisions alongside CPU.
Over the past ten years, Kubernetes has evolved into one of the foundational platforms underlying today’s modern IT infrastructure. Kubernetes allows organizations to manage large-scale, highly distributed, container-based workloads through its ability to provide an extendable architecture, as well as to automate a variety of tasks by providing a declarative model for defining resources.
As such, it provides a very scalable method for managing distributed workloads. However, although many organizations run their Kubernetes deployments within cloud environments that offer unlimited processing power, a significant transition to the use of edge computing is creating new operational requirements for Kubernetes users.
Edge computing involves running applications on devices or servers located close to where data is generated, rather than in a centralized cloud. Applications running at the edge must meet extremely low-latency requirements, be highly elastic, and perform predictably when subjected to large and unpredictable spikes in workload volume.
Because edge applications have limited processing capacity, memory, and network bandwidth, it is critical to use these resources efficiently and to scale edge applications rapidly in order to maintain both the quality of experience for end users and the reliability of services.
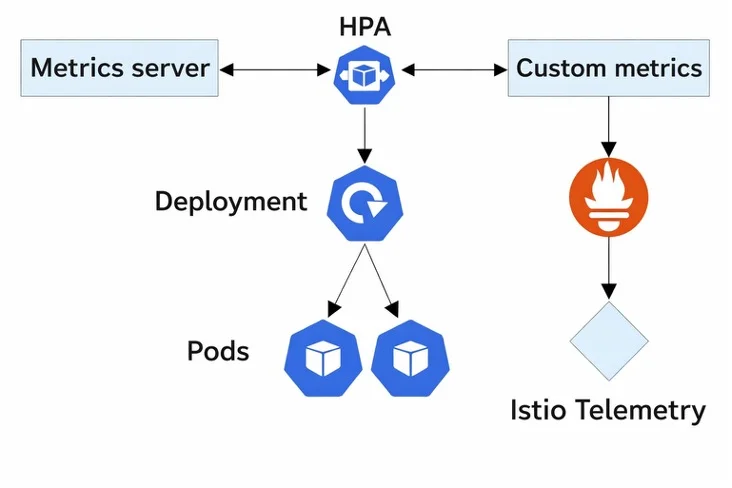
Kubernetes includes the Horizontal Pod Autoscaler (HPA) capability to dynamically adjust the number of pods within a deployment based on the current level of usage, including CPU, memory, and custom-defined metrics.
HPA is effective at reacting to observed traffic patterns in cloud environments; however, it is significantly less effective in managing the dynamic, bursty nature of edge workloads, where pod-scaling alternatives such as KEDA or custom autoscalers may be more suitable.
Figure 1: Horizontal pod autoscaler working
HPA's rigidness, its dependency upon lagging metrics, and its lack of contextual awareness commonly cause HPA's pod counts to scale too much, too little, or oscillate repeatedly. These behaviors can be very expensive and even dangerous when operating in resource-constrained environments.
I built an autoscaler using Custom Pod Autoscaler (CPA) for edge computing to address some of the limitations of HPA. CPA provides engineers the ability to develop their own algorithms, use combinations of multiple metrics, react quickly to changes in system state, and adjust the way they scale depending on the characteristics of the applications running on their clusters.



Comments (0)
No comments yet. Be the first!
Leave a Comment